About FinOps
FinOps is a platform that optimizes cloud costs and performance for any workload, providing effective cloud cost management for all types of organizations.
MegaOps FinOps primary capabilities
-
Pool Transparency
Pool breakdown and transparency across all business units, users, projects and individual cloud services. The customer sets soft and hard limits.
-
Simple multicloud asset provisioning workflow via dashboard or API
A single FinOps dashboard is used to manage hybrid clouds along with the virtual machines, volumes and network settings. Custom and mandatory tagging is supported. Custom TTL rules can be created to clear out workloads according to customer's policies.
-
Flexible alerts and notifications
Custom notifications about all related events, e.g. immediate workload volume increase, pool forecast overdraft or unusual behavior.
-
Swift user creation and business units distribution
Step-by-step guides for configuring user settings, organization subdivisions, pools and quotas assignments.
-
VM Power Schedules
The Power Schedule feature for cloud instances enables users to automate the management of virtual machine (VM) states by scheduling their start and stop times.
-
Optimal utilization of Reserved Instances, Savings Plans, and Spot Instances
A visualization of your compute usage covered by RIs and SPs versus your uncovered usage. By analyzing this data, you can identify potential savings by increasing your RI/SP coverage where beneficial.
-
S3 duplicate object finder
The S3 Duplicate Finder is designed to help optimize your AWS S3 storage usage by identifying and managing duplicate objects across your buckets.
More features are just around the corner and will be introduced shortly!
How it works
FinOps is dedicated to improve cloud usage experience but does not actively interfere with processes in your environment since it only requires Read-Only rights for the connected cloud account which is used as the main Data Source for all recommendations.
The following data is used:
-
Billing info - all details related to cloud expenses.
-
State of resources (for actively discoverable types) in the cloud - necessary for applying Constraints like TTL and Expense limit as well as for FinOp's Recommendation Engine.
-
Monitoring data from the cloud used for identifying underutilized instances.
Naturally, every cloud platform differs in the way the above data is obtained.
Alibaba
1. Billing information is acquired via Billing API:
-
https://www.alibabacloud.com/help/en/boa/latest/api-bssopenapi-2017-12-14-describeinstancebill
-
https://www.alibabacloud.com/help/en/boa/latest/api-bssopenapi-2017-12-14-queryuseromsdata
-
https://www.alibabacloud.com/help/en/boa/latest/api-bssopenapi-2017-12-14-querybilloverview
2. Cloud's Monitor service is used as the source of all monitoring data.
3. Resource discovery is performed via Discovery API:
-
https://www.alibabacloud.com/help/en/ecs/developer-reference/api-ecs-2014-05-26-describeinstances
-
https://www.alibabacloud.com/help/en/ecs/developer-reference/api-ecs-2014-05-26-describedisks
-
https://www.alibabacloud.com/help/en/rds/developer-reference/api-rds-2014-08-15-describedbinstances
Refer to this guide for more details.
Amazon Web Services (AWS)
1. Billing information is retrieved from the Data Exports located in a designated S3 bucket in the cloud:
2. Resource discovery is performed via Discovery API:
-
https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_DescribeInstances.html
-
https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_DescribeVolumes.html
-
https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_DescribeSnapshots.html
-
https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListBuckets.html
3. Amazon Cloud Watch is used as the source of monitoring data.
Refer to this guide for more details.
Azure
1. Billing information is acquired via Billing API:
2. Resource discovery is performed via Discovery API:
-
https://docs.microsoft.com/en-us/rest/api/compute/virtual-machines/list-all
-
https://docs.microsoft.com/en-us/rest/api/compute/disks/list
-
https://docs.microsoft.com/en-us/rest/api/compute/snapshots/list
-
https://docs.microsoft.com/en-us/rest/api/storagerp/storage-accounts/list
3. Cloud's Monitoring service is used as the source of all monitoring data.
Refer to this guide for more details.
GCP
1. Billing information is retrieved from the BigQuery service.
2. Cloud's Monitoring service is used as the source of all monitoring data.
3. Resource discovery is performed via Discovery API:
-
https://cloud.google.com/compute/docs/reference/rest/v1/instances/list
-
https://cloud.google.com/compute/docs/reference/rest/v1/disks/list
-
https://cloud.google.com/compute/docs/reference/rest/v1/snapshots/list
-
https://cloud.google.com/storage/docs/json_api/v1/buckets/list
-
https://cloud.google.com/compute/docs/reference/rest/v1/addresses/list
Refer to this guide for more details.
Kubernetes
To enable cost management and FinOps capabilities for your Kubernetes cluster, you need to deploy a software component that collects information about running pods and converts it into cost metrics. Refer to this guide for more details.
This software is open-source, free of malware, and requires read-only access to Kubernetes metadata and performance metrics. Please review the code and find a detailed description on GitHub.

-
Home. Find your organization’s current spending and projected expenses for the upcoming month. Details about Home page.
-
Recommendations. Get practical information about suggesting services and features available in FinOps. Find a brief description and other pertinent information in the cards to help you assess the situation quickly. How to use recommendation cards.
-
Resources. Observe the expenses for all resources across all connected clouds within the organization for the selected period. Organize and categorize resources based on your specific requirements.
-
Pools. View pools with limits or projected expenses that require your attention. Manage pools using the available features on this page.
-
Shared Environments. This feature enables you to focus more on application logic rather than infrastructure management. Use this page to book cloud environments for specific periods to allow multiple users or applications to access and use the same underlying infrastructure.

-
FinOps. View a breakdown chart that visualizes your expenses over time, get a visual or analytical representation of costs, and become familiar with the concepts of FinOps and MLOps.
-
MLOps. Keep track of your tasks, machine learning models, and datasets. Define hyperparameters and automatically run your training code on the Hypertuning page. Share specific artifacts with your team members.
-
Policies. Identify and respond to unusual patterns or deviations from normal behavior, control costs and manage resources efficiently, implement robust tagging policies, and manage the resource lifecycle and automated power on/off schedules effectively.
-
Sandbox. Evaluate CPU and memory usage by k8s resources, view applied recommendations, and compare instance pricing across different clouds.
-
System. Assign roles to users for resource management, integrate with various services, and view events.
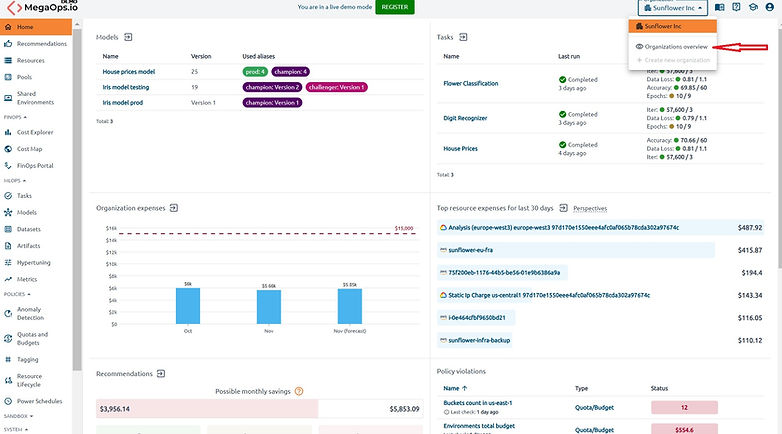
In case there are several organizations registered in OptScale that the user is considered to be a part of, clicking on the Organization field → Organization overview in the top right corner of the page will redirected to a new view containing a matrix of key information on each organization.
Organizations that require attention and optimization are marked in red.

Documentation, product tour, and profile buttons#
On the right of the Organization selector find the Documentation, Product tour, and Community documentation buttons.

Home Page
A Home page provides quick access to the most popular pages of the solution.

For convenience, a button for going to the main page of the section is implemented. Use it to get more detailed information.
In most tables presented in the sections, the rows are clickable, which allows to get quick access to the information about an item.
The page is divided into 7 sections:
-
Organization expenses. See the total expenses of the previous month, the expenses of the current month, and this month forecast. A red line on the chart shows the expenses limit.

-
Top resource expenses for last 30 days. Control the resources with the highest expenses. In addition, view the Perspectives or "Go to the resources" via buttons near the caption.

-
Recommendations. Find summary cards with possible monthly savings, and expenses separated to categories cost, security, and critical on the Recommendations section. Click on the card caption to get details on the Recommendations page.

-
Policy violations. Pay special attention to the status field. If it is red, the policy is violated.

-
Pools requiring attention. Navigate between tabs on the Pools requiring attention section to get the "Exceeded limit" or "Forecast overspend" pools. Use buttons in the Actions column to see resources list and see in cost explorer.

-
Tasks. View the status and metrics of the last run.

-
Models. Keep track of your machine learning models.

Recommendations
FinOps features a set of automated tools for ongoing optimization of registered Data Sources. The section is intended to help maintain awareness of the less apparent deficiencies of the infrastructure like configuration flaws and security risks.
Force check and check time
At the moment, a check-up is performed every 3 hours and the results are reflected in the Recommendations hub, which is accessible via the left sidebar of the main page. A user with the Organization manager role can initialize a Force check that will immediately run the Data Sources' evaluation sequence.
Alternatively, find the last and next check time in the Summary Cards.

Filtering
There are two types of recommendations that are featured in OptScale: savings, security. Additionally, there is an option to view critical, non-empty, and all recommendations. Refine the recommendations using the Categories filter if necessary. By default, all recommendations are displayed.

In addition to filtering by categories, the page allows selection of Data Sources and Applicable services.
Summary cards
Use Summary Cards to get an at-a-glance overview of important details, such as total expenses, check time, savings, duplicates found, etc.
This icon shows that you can click on the Summary Card to get detailed information.

Color schema and recommendation cards
Pay special attention to the color schema of the page.

In all other situations, the card is white.
Detailed instructions on how to use recommendation cards find on our web-site.
Settings
Adjusting parameters is beneficial as it allows for fine-tuning and optimizing results to better meet specific goals or conditions. The set of parameters varies depending on the card, so set the values according to your needs.

Security Recommendations
Inactive IAM users
Users that have not been active for more than 90 days may be considered obsolete and become subject to deletion due to the potential security risks they produce for the organization as they can be compromised and become access points for malicious users.
The list of inactive users can be downloaded in the json format for subsequent automated processing with the help of Cleanup Scripts.
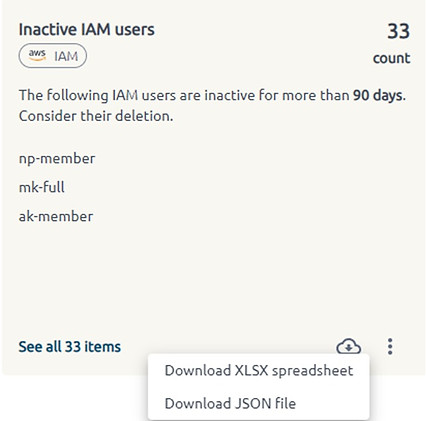
The number of days is a custom parameter. Use settings to change it.
Instances with insecure Security Groups settings
Security check that browses through the resources to find network vulnerabilities and provides a list of instances that are liable to RDP/SSH hacking.
Insecure ports and permissions:
-
port tcp/22
-
port tcp/3389
-
all inbound traffic
with one of:
-
CidrIp: 0.0.0.0/0
-
CidrIpv6: ::/0
AWS
-
Describe regions: ec2.describe_regions()
-
Describe instances: ec2.describe_instances()
-
Describe security groups: ec2.describe_security_groups()
Azure
-
Describe instances: compute.virtual_machines.list_all()
-
Describe security groups: network.network_security_groups.list_all()
The list of insecure SGs can be downloaded in the json format for subsequent automated processing.

IAM users with unused console access
The active IAM users that have console access turned on, but have not been using it for more than 90 days are in the list. Consider revoking console access to increase security.
The parameter in bold is a custom parameter. Use settings to change it.
Public S3 buckets
The S3 buckets in the list are public. Please ensure that the buckets use the correct policies and are not publicly accessible unless explicitly required.
Savings Optimization Recommendations
Abandoned Instances
Instances that have the average CPU consumpsion less than 5% and the network traffic below 1000 bytes/s for the last 7 days.
We recommend to terminate these instances to reduce expenses.
The parameters in bold are custom parameters. Use settings to change them.
Obsolete Images
Images that have not been used for a while might be subject to deletion, which would unlock the underlying snapshots.
Selection criteria:
-
image creation date was more than 1 week ago.
-
there has been no instances created from/related to this image in the past 7 days.
The list of obsolete images can be downloaded in the json format for subsequent automated processing with the help of Cleanup Scripts.

The parameter in bold is a custom parameter. Use settings to change it.
Obsolete Snapshots
Redundant and old snapshots will save up on storage expenses if deleted. The list of snapshots can be downloaded from OptScale in JSON format to be used in further implementations like clean-up scripts and maintenance procedures.
Selection criteria:
-
its source EBS volume does not exist anymore,
-
there are no AMIs created from this EBS snapshot,
-
it has not been used for volume creation for the last 4 days.
The list of obsolete snapshots can be downloaded in the json format for subsequent automated processing with the help of Cleanup Scripts.

The parameter in bold is a custom parameter. Use settings to change it.
Obsolete IPs
Obsolete IPs can be tracked for Alibaba, Azure and AWS clouds.
Selection criteria:
-
IP was created more than 7 days ago,
-
IP has not been used during last 7 days,
-
it costs money to be kept.
The parameter in bold is a custom parameter. Use settings to change it.
Not attached volumes
Notification about volumes that have not been attached for more than one day. These are considered to be forgotten or no longer relevant; deletion of such resources may be advised.
The list of unattached volumes can be downloaded in the json format for subsequent automated processing with the help of Cleanup Scripts.

Underutilized instances
This recommendation is aimed at detection of underutilized instances in AWS and Azure and suggests more suitable flavors for these machines.
Instance is considered to be underutilized if:
-
it is active.
-
it exists for more than 3 days.
-
its CPU metric average for past 3 days is less than 80%.

The parameter in bold is a custom parameter. Use settings to change it.
Reserved Instances opportunities
This card contains instances that:
-
are active.
-
have sustainable compute consumers more than 90 days.
-
have not been covered with Reserved Instances or Saving Plans.
For such instances, it is recommended to consider purchasing Reserved Instances to save on compute usage.
Check RI/SP Coverage to see the detailed breakdown of current reservations.
The parameter in bold is a custom parameter. Use settings to change it.
Abandoned Kinesis Streams
Kinesis Streams with provisioned Shard capacity that have not performed operations in the last 7 days are listed on this card.
Consider removing them to reduce expenses.
The parameter in bold is a custom parameter. Use settings to change it.
Instances with migration opportunities
This card shows opportunities to migrate instances if OptScale detects that the same instance type is cheaper in a geographically close region (within the same continent).
Some of your active instances may cost less in another nearby region with the same specifications. Consider migrating them to the recommended region to reduce expenses.
Instances for shutdown
Some of your instances have an inactivity pattern which allows you to set up an on/off power schedule (average CPU consumption is less than 5% and network traffic below 1000 bytes/s for the last 14 days). Consider creating a power schedule to reduce expenses.
The parameters in bold are custom parameters. Use settings to change them.
Instances with Spot (Preemptible) opportunities
The instances that:
-
have been running for the last 3 days,
-
have existed for less than 6 hours,
-
were not created as Spot (or Preemptible) Instances
are in the list.
Consider using Spot (Preemptible) Instances.
To change the check period click SETTINGS on the card.

The parameters in bold are custom parameters. Use settings to change them.
Underutilized RDS Instances
An underutilized instance is one average CPU consumption less than 80% for the last 3 days.
OptScale detects such active RDS instances and lists them on the card.
Consider switching to the recommended size from the same family to reduce expenses.
Change the Rightsizing strategy by click on the Settings on the card.

The parameters in bold are custom parameters. Use settings to change them.
Obsolete Snapshot Chains
Some snapshot chains do not have source volumes, images created from their snapshots and have not been used for volume creation for the last 3 days. Consider their deletion to save on snapshot storage expenses.
Change the check period in the card's Settings.
The parameter in bold is a custom parameter. Use settings to change it.
Instances with Subscription opportunities
The instances in the list are active and have been identified as sustained compute consumers (for more than 90 days) but are not covered by Subscription or Savings Plans.
Consider purchasing Subscriptions to reduce compute costs.
Change the check period in the card's Settings.
The parameter in bold is a custom parameter. Use settings to change it.
Not deallocated Instances
Detection of inactive non-deallocated machines that have not been running for more than 1 day and still billed by the cloud.
The list of non-deallocated VMs can be downloaded in the json format for subsequent automated processing with the help of Cleanup Scripts.
Change the check period in the card's Settings.

The parameter in bold is a custom parameter. Use settings to change it.
Instances eligible for generation upgrade
Upgrade older generation instances to the latest generation within the same family.
Abandoned Amazon S3 buckets
The bucket is abandoned is the average data size has been less than 1024 megabytes, Tier1 requests quantity has been less than 100, and GET requests quantity has been less than 2000 for the last 7 days
It is recommended to delete it to reduce expenses.
Change the check period and other parameters in the card's Settings.
The parameters in bold are custom parameters. Use settings to change them.
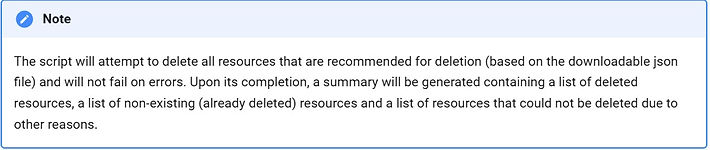
Clean-up Scripts based on Recommendations
Below are the instructions on how to use the clean-up scripts found in the "Recommendations" section.
Alibaba
Requirements
-
Aliyun. Installation guide.
-
jq - the package allows executing json scripts with bash. Download page.
Action plan
1. Install the requirements on a machine running Linux OS.
2. Sign in aliyun:

3. Configure timeouts:
aliyun configure set --read-timeout 20 --connect-timeout 20 --retry-count 3
4. Run script bash <script_name> <path to recommendation json file>.
5. Run script on Alibaba shell:
-
Open console → Online Linux Shell.
-
Copy script and recomendation json file via the Upload/Download files button.
-
Run script as follows: bash <script_name> <path to recommendation json file>. Use absolute paths or perform cd before execution.
AWS Source
Requirements
-
AWS cli v2. Official Amazon User Guide.
-
jq - the package allows executing json scripts with bash. Download page from the developer.
Action plan
1. Install the requirements on a machine running Linux OS. 2. Configure the AWS Command Line Interface. (Run the aws configure command. For more info, please refer to the following section of the AWS User Guide) 3. Download the script from the corresponding subsection of the OptScale's "Recommendations" page.

4. From the same page, download the json file containing a list of all resources that are recommended for deletion. 5. Run the script as follows: bash <script_name> <path to json file>
Azure Source
Requirements
-
Azure cli. Official Microsoft User Guide.
-
jq - the package allows executing json scripts with bash. Download page.
Action plan
-
Install the requirements on a machine running Linux OS.
-
Sign in with the Azure cli.
-
Download the script from the corresponding subsection of the OptScale's "Recommendations" page.
-
From the same page, download the json file containing a list of all resources that are recommended for deletion.
-
Run the script as follows: bash <script_name> <path to json file>.
Action plan when using Azure Shell
-
Open Azure shell.
-
Download the script and the json file from the corresponding subsection of the OptScale's "Recommendations" page.
-
Copy these files via the Upload/Download files button. The files will be placed in /usr/csuser/clouddrive.
-
Run the script as follows: bash <script_name> <path to json file> using absolute paths or navigate to the necessary folder before executing.
GCP Source
Requirements
-
Gcloud cli. gcloud CLI overview.
-
jq - the package allows executing json scripts with bash. Download page.
Action plan
1. Install requirements on a machine running Linux OS.
2. Configure gcloud: run gcloud init. See more info.
3. Run script bash <script_name> <path to recommendation json file>.
Archived Recommendations
If a recommendation has been applied or has become irrelevant, it will be moved to the archive. To view it, click the Archive button in the top-right corner of the Recommendations page.

Clusters
Oftentimes a set of cloud resources that serve a common purpose can be viewed as a single entity from the user perspective. In many cases, resources are not intended to run independently and are created/terminated simultaneously while sharing an attribute like tag value that connects them together. Such groups of resources can be merged into clusters making them stand-alone virtual resources in OptScale for better management options.
Sub-resources are added into clusters automatically based on cluster type definitions that are created by the user with the Organization Manager role.
To set up a new cluster, go to the Configure cluster types on the right-hand corner of the Resources page and click the Add button on the Cluster Types page.

Please define new cluster type name (will be used as the type of created cluster resources) and clusterization tag key. Once created, this cluster type will be applied to newly discovered resources. Existing resources can be clusterized using the Re-apply cluster types action.
A definition consists of the following two parameters:
-
cluster type name - must be unique within the organization.
-
tag key - a common parameter to be used for consolidating sub-resources.

Cluster type definitions are automatically applied to resources upon their discovery in FinOps (through billing or direct discovery) for consolidation even before any existing assignment rules take effect.
The list of cluster types is prioritized to avoid any conflicts. A new cluster type is placed at the bottom of the list so it does not affect existing clusters and can be prioritized manually later on.
Clicking on the Re-apply cluster types button triggers a new resource allocation sequence that uses the current order of cluster types as a rule.
A cluster type can be deleted from the same page. Upon deletion, all clusters of this type are disassembled as well.
In the Resources section, items that are part of a cluster are marked with the symbol to distinguish them among usual resources.

Clicking on their names will bring up the Cluster Details page that lists all included sub-resources, their total expenses, and constraints that are applied throughout the cluster.

Shared Environments
FinOps Shared Environments provide a signle point to manage your production and test environments. These resources are meant to be acquired for exclusive utilization by an organization member or a team member only temporarily and then released making them available again. The common use cases are release stands and demo environments where the availability of a range of components (e.g. for deploying some software version) has to be controlled in order to eliminate accidental breaking or loss of interconnections.
Depending on your cloud platform, there are two ways to create a Shared Environment in the product:
-
if you have a connected Cloud Account, you can easily mark the resources as Shared Environments
-
or you can simply add new Shared Environment, not related to any connected Cloud Account, from the Shared Environments page.
Mark existing cloud resources as Shared Environments
At first, when an Organization is added into FinOps, the section is empty and new Shared Environments have to be created manually by a user with the Organization Manager role from the scope of shareable resources that can only include Instances or FinOps clusters.
To be able to manage your cloud resource as environment, select the resource on the Resources page and click Mark as Shared Environment.

The marked environment will appear on the Shared Environments page. The resource is now available for booking, and you can proceed with using webhooks and integrating with your CI/CD.
Create new Shared Environment
To create a new Environment in OptScale select Shared Environments at the left sidebar of the main page and click Add.

You will be prompted to input a Name and a Resource type, set if SSH access is required, specify additional properties for a new Shared Environment. Dy defauls, the solution requests to add the Description, IP, and Software. Use Add Property button in case if you want to add extra properties.

A newly created entity will be added to this section and listed in a table providing information about a Pool that it belongs to, its Status which can be In use, Available, or Unavailable, Upcoming bookings, related Software and Jira tickets (optional).

Action buttons
The following action buttons allow to control an existing environment:
- a Shared Environment can be booked for a selected period of time.

Detailed instructions on how to organize access to shared resources using FinOps find on our website.
Resource Assignment
Strong resource assignment improves efficiency, reduces costs, enhances accountability, and helps projects stay on track, all of which contribute to higher overall success rates in organizational and project management contexts.
Newly created resources are distributed among pools based on assignment rules. If they have certain tags, they will immediately be assigned to the appropriate pool as soon as they are first discovered. If they do not belong to any pool, they will be assigned to the Data Source pool. The Data Source pool is created when the Data Source is connected.
FinOps allows you to manage assignment rules by viewing, creating, editing, and changing their priority.
Assignment Rules Table
Go to the Pools page and click on the Configure Assignment Rules button.

Assignment Rules is a centralized interface for viewing and managing all existing assignment rules in the system. This page provides a list of rules displayed in a tabular format for easy navigation and interaction. Users can view the status of each rule and take appropriate actions directly from this page.

All assignment rules are displayed in a table, allowing easy browsing and management. The general actions Add and Re-apply Ruleset are placed above the table. Search functionality is available based on criteria such as Name, Assigned to, Conditions, and Priority. For ease of navigation, the page supports pagination, allowing to view assignment rules in manageable chunks. All data columns are sortable.
Each row represents a specific rule and includes details such as:
-
a descriptive name for the rule,
-
the pool and owner to whom the resource is assigned,
-
a summary of the conditions that trigger the rule,
-
the priority used to apply assignment rules to resources,
-
actions.
Use the Actions column buttons to manage rules:

Add Assignment Rule
There are two ways to add an Assignment Rule: through the Assignment Rules page or the Resource page. On the Resource page, you get a specialized version of the Add Automatic Resource Assignment Rule Form with pre-filled fields based on your resource information.
Assignment Rules page
The Add Automatic Resource Assignment Rule Form is used to define new assignment rules for automatic resource allocation based on specified conditions. The form is divided into sections to collect relevant information for creating an assignment rule, including the rule's name, status, conditions, and assignment targets.


Input a Name for the new automatic resource assignment rule as well as the Conditions that have to be fulfilled in order for the rule to become applicable. Add and remove conditions to suit your needs. As the result, a matching resource will be included into the selected Target Pool and assigned to an Owner.
A newly created rule is always prioritized across the organization and is put at the top of the list for the discovered resources to be checked against its conditions first. If these are not satisfied, a resource will be checked against the remaining rules in descending order until one is found applicable.
Resources page
This form is a specialized version of the Add Automatic Resource Assignment Rule Form from the Assignment Rules page. The page is accessible by clicking the Add Assignment Rule button directly from a specific resource's details page.

Its purpose is to simplify the creation of assignment rules for a particular resource by pre-filling relevant fields with the resource's existing data.

Re-apply Ruleset
Re-apply Ruleset - initiates a new check of the already assigned resources against the current ruleset. Resources will be reorganized accordingly even if they were explicitly assigned otherwise before. This feature helps manage assignments, especially when rules are edited, new ones are added, or the priority of existing rules is changed.
To start the process, click the Re-apply Rules button. A side modal opens.

Select whether you want to re-apply to the entire organization or a specific pool. In the second selection, specify a pool and, if necessary, enable the With sub-pools checkbox. The Run button starts the process and closes the modal, while the request continues to run in the background. The Cancel button simply closes the modal without performing any actions.
Pool-related assignment rules
This feature provides quick access to the assignment rules that apply specifically to a given pool. It helps users understand how resources are being assigned and managed within the pool, ensuring transparency and simplifying rule verification and modification by centralizing relevant rules in one place.
To find a list of assignment rules associated with the selected pool, open the detailed page of the desired pool from the Pools page.

Each rule entry includes the Name, Owner, and Conditions of the rule, providing a clear overview of the rule configurations.
The Conditions column offers a detailed summary of the conditions defined for each rule, including condition types such as Name/ID contains, Tag is, or Source is.
Click the See all assignment rules link at the bottom of the section to navigate to the main assignment rules listing page, where all rules across different pools can be managed.
Resources constraints & Pool constraint policies
To address the ever-dynamic cloud infrastructure where resources are being created and deleted continuously, FinOps introduces a set of tools to help limit the related expenses and the lifetime of individual assets. The following feature is implemented in form of constraints that User can set for a specific resource or generally for a Pool.
There are two constraint types that can be set:
-
TTL - time to live, a resource should not live more than the specified period. For a resource, specify a date and time. For a pool, input an integer between 1 and 720 hours.
-
Daily expenses limit - resource spendings should not exceed the specified amount in dollars. Input as integer, min $ 1, 0 - unlimited.
When FinOps discovers active resources in the connected source, it checks that they don't violate any existing Pool constraints that were applied as policies before.
When a resource hits a constraint, both manager and owner of the resource are alerted via email. If a resource is unassigned - alerts are sent to the organization managers. On the Pools page an exclamation mark will appear next to the pool name.
Resources constraints
Navigate to the desired asset by selecting the appropriate resource on the Resources page.

To assign constraints to resources, go to the Constraints tab on the selected resource's page.
On the Constraints tab, use the slider to enable/disable the current setting. Click on the image below the constraint's name and fill in the values for TTL or the Daily expense limit in the fields.

If a resource doesn't have a specific constraint set, it inherits the policies from its Pool. However, resource owner or manager can override an existing Pool constraint policy for an individual resource by issuing a custom constraint for any given asset.
Pool constraint policies
This is a more high-level setting that facilitates the flow in a way that allows implementing policies for entire Pools instead of a single resource. Thus, a manager can enforce all resources in the Pool to share constraints so that they are applied to all resources in this Pool, while custom resource-specific constraints can still exist and yet override the general policy.
Click on Pools in the left sidebar and choose a Pool group or its sub Pool.

Click on the image next to a constraint's name and fill in the values for TTL or the Daily expense limit in the empty fields. Use the slider to enable/disable the current setting.
Pool deletion
The Pool structure can be changed by deleting unnecessary Pools via the dedicated section of the main page. This option is not available for Pools that have sub-Pools - latter have to be deleted first.
Use button from the Actions menu to delete a Pool.


When a Pool is deleted:
-
all resources are reassigned to its parent Pool;
-
all rules that used to point to this Pool are redirected to its root.
Integrations
Google Calendar
Integrating Google Calendar to display shareable resource booking intervals as events allows users to view and manage availability in real time. Each booked interval appears as a Google Calendar event, making it easy to see open and reserved slots at a glance. This setup enables streamlined scheduling, letting users quickly check and share resource availability with others through a familiar calendar interface.
Follow these steps to connect Google Calendar to FinOps:
Prepare your Google Calendar
1. Create or choose one of the existing secondary calendars in your Google Calendar
2. Share it with the FinOps service account
service@megaops.io to do this:
-
Select the calendar
-
Open the Calendar Settings
-
Navigate to the Share with specific people or groups section
-
Click the Add people and groups button

-
Add the email address: support@megaops.io and select the Make changes to events permission.

3. Copy the Calendar ID from the Integrate calendar section.

Connect the Calendar to FinOps
1. Open the Integrations page and click the CONNECT CALENDAR button
2. Paste the Calendar ID into the opened side modal

3. Click the Connect button to view your Shared Environment schedules directly in the Google Calendar.
Slack App
Slack has become a popular communication tool that brings Managers, DevOps and Engineering team members together in their everyday tasks. FinOps can be integrated into Slack as an application to provide a range of notifications, monitoring and management options in a familiar interface to engage everyone in a more efficient FinOps strategy without delays that are often caused by the necessity to access several platforms.
To add our app to your Workspace in Slack and connect it to your FinOps account:
1. Access FinOps's UI (https://my.finops.com/, by default).
2. Log in as the user that you want to assign the Slack app to. (Re-login as a preferred user to get Slack notifications depending on the Organization Role).
3. Go to <finops_url>/slacker/v2/install (https://my.finops.com/slacker/v2/install).
4. Click on the Add to Slack button.
5. Click Allow on the next page to add the permissions and be redirected to the Slack desktop app or its browser version.
Quickstart
MLOps, or Machine Learning Operations, is a set of practices that aims to streamline and optimize the lifecycle of machine learning models. It integrates elements from machine learning, DevOps, and data engineering to enhance the efficiency and effectiveness of deploying, monitoring, and maintaining ML models in production environments. MLOps enables developers to streamline the machine learning development process from experimentation to production. This includes automating the machine learning pipeline, from data collection and model training to deployment and monitoring. This automation helps reduce manual errors and improve efficiency. Our team added this feature to FinOps. It can found in the MLOps section. This section provides everything you need to successfully work with machine learning models.
Use the Community documentation to get a brief description of each page.
There are two essential concepts in FinOps MLOps: tasks and runs:
-
A run is a separate execution of your training code. A new run entry appears in FinOps for each run. Run is a single iteration of a task. This can include the process of training a model on a given dataset using specific parameters and algorithms. Each run records the settings, data, results, and metrics, allowing researchers and developers to track model performance and compare different approaches.
-
A task allows you to group several runs into one entity so that they can be conveniently viewed.
Follow this sequence of steps to successfully work with MLOps:
-
Create a task
-
Create metrics
-
Assign metrics to the task
-
Integrate your training code with FinOps.
Tutorial
Step 1. Prepare task and metrics
Create a Task
To add a new Task, go to the Tasks page and click the Add button to set up and profile the Task you'd like to manage.

When creating a new Task in FinOps, specify: Task name, key, description, owner, and tracked metrics.

Create Metrics
To add a new Metric, go to the Metrics page and click the Add button.

When adding a Metric in FinOps, you need to specify the following details:
-
Name: This is the name that will display in the interface.
-
Key: A unique metric identifier, used in commands like send.
-
Tendency: Choose either “Less is better” or “More is better” to define the desired trend.
-
Target value: The target value you aim to achieve for this metric.
-
Aggregate function: This function will apply if multiple values are recorded for the metric within the same second.

These settings help ensure that metrics are tracked consistently and accurately across your tasks and runs.
Assign Metrics to the Task
To assign a metric to a Task in FinOps:
1. Open the Task by going to the Tasks page and clicking on the Task name
2. Click the Configure button
3. Select the Metrics tab
4. Add the desired metrics.

This allows you to configure and assign specific metrics to the Task for tracking and analysis.
Step 2. Integrate your training code with FinOps
Install finops_arcee
The finops_arcee is a Python package which integrates ML tasks with FinOps by automatically collecting executor metadata from the cloud and processing stats.
It requires Python 3.7+ to run. You can install finops_arcee from PyPI on the instance where the training will occur. If it's not already installed, use:
pip install finops_arcee
This setup ensures that finops_arcee can collect and report relevant metrics and metadata during ML tasks.
Commands and examples
Find examples of specialized code prepared by our team at the https://github.com/megaops/finops_arcee/tree/main/examples.
To view all available commands:
1. Go to the Tasks page of the MLOps section of the menu
2. Click the Task name you want to run
3. Click the Profiling Integration button of the opened page.

The Profiling Integrations side modal provides a comprehensive list of commands available for profiling and integration with FinOps.

Please pay special attention to the import and initialization commands. They are required.
Import
Import the finops_arcee module into your training code as follows:
import finops_arcee as arcee
Initialization
To initialize an finops_arcee collector, you need to provide both a profiling token and a task key for which you want to collect data. This ensures that the data collected is associated with the
correct Task and can be accurately monitored and analyzed in FinOps.
The profiling token is shared across the organization, meaning it is common to all users and tasks within that organization. The task key is specified when creating a Task.
Find the profiling token and task key in the Profiling Integration side modal. To access it, click the task name in the list on the Tasks page, then click the Profiling Integration button.

To initialize the collector using a context manager, use the following code snippet:
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# some code
Alternatively, to get more control over error catching and execution finishing, you can initialize the collector using a corresponding method. Note that this method will require you to manually handle errors or terminate arcee execution using the error and finish methods.
arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# some code
arcee.finish()
# or in case of error
arcee.error()
This information is provided in the Profiling Integration side modal. You can simply copy the command. Please note that the command changes depending on the selected task.
FinOps from open-source
If you are using FinOps from the open-source version, you need to specify the endpoint_url parameter in the init method. The address you provide must be publicly accessible to ensure proper communication between the finops_arcee collector and the FinOps server.
Send metrics
To send metrics, use the send method with the following parameter:
-
data (dict, required): a dictionary of metric names and their respective values (note that metric data values should be numeric).
-
arcee.send({ "metric_key_1": value_1, "metric_key_2": value_2 })
Example:
# Import the finops_arcee module
import finops_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Send metric
arcee.send({ "accuracy": 71.44, "loss": 0.37 })
Finish task run
To finish a run, use the finish method
arcee.finish()
Fail task run
To fail a run, use the error method
arcee.error()
Execute instrumented training code
Run your script with the command:
python training_code.py
If the script runs successfully, the corresponding run will appear with a Running status under the associated Task in FinOps.
This indicates that finops_arcee is actively tracking and sending metrics during execution.
Step 3. Extended settings. Commands and examples
Add hyperparameters
To add hyperparameters, use the hyperparam method with the following parameters:
-
key (str, required): the hyperparameter name.
-
value (str | number, required): the hyperparameter value.
arcee.hyperparam(key, value)
Example:
# Import the finops_arcee module
import optscale_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Add hyperparam
arcee.hyperparam("epochs", "10")
Tag task run
To tag a run, use the tag method with the following parameters:
-
key (str, required): the tag name.
-
value (str | number, required): the tag value.
arcee.tag(key, value)
Example:
# Import the optscale_arcee module
import optscale_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Add run tags
arcee.tag("purpose", "testing")
arcee.tag("code_commit", "commit_id")
Add milestone
To add a milestone, use the milestone method with the following parameter:
-
name (str, required): the milestone name.
arcee.milestone(name)
Example:
# Import the optscale_arcee module
import optscale_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Download training data
# Add milestone with name "Download training data"
arcee.milestone("Download training data")
...
# Download test data
# Add milestone with name "Download test data"
arcee.milestone("Download test data")
...
Add stage
To add a stage, use the stage method with the following parameter:
-
name (str, required): the stage name.
arcee.stage(name)
Example:
# Import the optscale_arcee module
import optscale_arcee as arcee
...
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Download training data
# Add stage with name "preparing"
arcee.stage("preparing")
...
Log datasets
To log a dataset, use the dataset method with the following parameters:
-
path (str, required): the dataset path
-
name (str, optional): the dataset name
-
description (str, optional): the dataset description
-
labels (list, optional): the dataset labels.
arcee.dataset(path, name, description, labels)
This method works properly, regardless of whether the dataset exists in FinOps.
Let's take a look at the possible scenarios.
Log a dataset known to FinOps
Follow the instruction to add a new Dataset.
To log the dataset use the path from the Datasets page as the path parameter in the dataset(path) method.
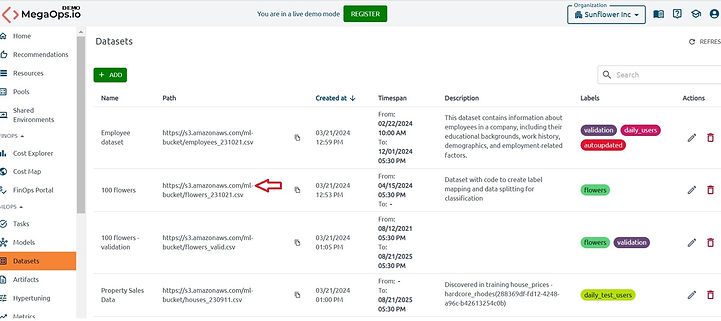
Example:
In the example we'll log the dataset shown on the screenshot with the name “100 flowers“ and
the path “https://s3.amazonaws.com/ml-bucket/flowers_231021.csv“.
# Import the finops_arcee module
import finops_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Log existing dataset
arcee.dataset("https://s3.amazonaws.com/ml-bucket/flowers_231021.csv")
Log a dataset unknown to FinOps
If the dataset is unknown to FinOps, simply specify the desired path as a parameter in dataset(path), and the dataset will be registered automatically.
Update the dataset information on the Datasets page by clicking the Edit icon.
Create models and set additional model parameters
Create models
To create a model, use the model method with the following parameters:
-
key (str, required): the unique model key
-
path (str, optional): the run model path
arcee.model(key, path)
Example:
We have created the model with the name “Iris model prod“ and the key = “iris_model_prod“

To create a version of the “Iris model prod“ model:
# Import the finops_arcee module
import finops_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Create “Iris model prod“ model version
arcee.model("iris_model_prod", "https://s3.amazonaws.com/ml-bucket/flowers_231021.pkl")
Each model can have multiple versions. When a new model is added, it starts at version "1". If additional models are registered under the same model key, the version number increments automatically with each new registration.
Set additional parameters for the model
Model version
To set a custom model version, use the model_version method with the following parameter:
-
version (str, required): the version name.
arcee.model_version(version)
Model version alias
Model version aliases allow you to assign a mutable, named reference to a particular version of a registered model. Each alias should be unique within the model’s scope. If an alias is already in use, it should be reassigned.
To set a model version alias, use the model_version_alias method with the following
parameter:
-
alias (str, required): the alias name.
-
arcee.model_version_alias(alias)
TAG
To add tags to a model version, use the model_version_tag method with the following parameters:
-
key (str, required): the tag name.
-
value (str, required): the tag value.
arcee.model_version_tag(key, value)
Example:
# Import the finops_arcee module
import finops_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Create “Iris model prod“ model version
arcee.model("iris_model_prod", "https://s3.amazonaws.com/ml-bucket/flowers_231021.pkl")
# Set custom version name
arcee.model_version("My custom version")
# Set model verion alias
arcee.model_version_alias("winner")
# Set model verion tag
arcee.model_version_tag("env", "staging")
Create artifacts
To create an artifact, use the artifact method with the following parameters:
-
path (str, required): the run artifact path.
-
name (str, optional): the artifact name.
-
description (str, optional): the artifact description.
-
tags (dict, optional): the artifact tags.
arcee.artifact(path, name, description, tags)
Example:
# Import the finops_arcee module
import optscale_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
#Create Accuracy line chart artifact
arcee.artifact("https://s3/ml-bucket/artifacts/AccuracyChart.png",
name="Accuracy line chart",
description="The dependence of accuracy on the time",
tags={"env": "staging"})
Set artifact tag
To add a tag to an artifact, use the artifact_tag method with the following parameters:
-
path (str, required): the run artifact path.
-
key (str, required): the tag name.
-
value (str, required): the tag value.
arcee.artifact_tag(path, key, value)
Example:
# Import the optscale_arcee module
import optscale_arcee as arcee
# Initialize the collector using a context manager
with arcee.init("YOUR-PROFILING-TOKEN", "YOUR-TASK-KEY"):
# Add artifact tag
arcee.artifact_tag("https://s3/ml-bucket/artifacts/AccuracyChart.png",
"env", "staging demo")
Tips
How to create a dataset
1. Open the Datasets page and click the Add button

2. When adding a dataset, specify:
-
Path - the dataset path, providing information about the dataset’s source. Used in the dataset method.
-
Name - the name of the dataset, e.g. "iris_data"
-
Timespan from/ Timespan to - the dataset validity time
-
Description - the dataset description
-
Labels - the dataset labels.

How to create a model
1. Open the Models page and click the Add button

2. Specify in the Add Model page:
-
Name - the name with which the model will be displayed in the interface
-
Key - the model identifier which is used in the model command
-
Description - the model description
-
Tags - the model tags.

Tasks page
A task is the primary unit of organization and access control for runs; all runs belong to a task. Tasks let you visualize, search for, and compare runs and access run metadata for analysis. Find already created tasks on the Tasks page of the MLOps section of the menu.

The Tasks page contains a list of profiled tasks, including their key, status, goals, expenses, and output metrics from the most recent run.

You can also set filters and take action. The Profiling Integration action gives you complete instructions on successfully launching code on your instance to get the result.
Use Manage Metrics to add or edit metrics. Here, you can define a set of metrics against which every module should be evaluated. You can also set a target value and tendency for each captured metric.
Behind the Executors button hides the Executors’ list, showing you compute resources used to run your ML activities.
You can see information about some tasks by clicking on its name.


Summary cards contain information about the last run status, last run duration, lifetime cost (the cost of all runs in the task), and recommendations (recommendations for instances used as executors).

Tracked Metrics are a graphical representation of all runs and specific numbers for the last run. The green circle indicates that the metric has reached the target value under the tendency, while the brown one indicates that it has not. After that, the last run value/target metric value line values for all task runs follow.

If the executor is known to FinOps, you will receive complete information about it and its expenses. Please note that supported clouds are AWS, Azure, Alibaba, and GCP. If the executor is unknown to the FinOps, then some information about it will be unavailable. The section will look like it is shown below:

How to view training results
The results of the training code are displayed in FinOps. Find them in the Home or MLOps section. Use the Community documentation to get a brief description of each page.
Information on the latest run can be found in four places:
-
Home page → Tasks section. View a table displaying the status, execution time, and metric values of the last run for recently used tasks.
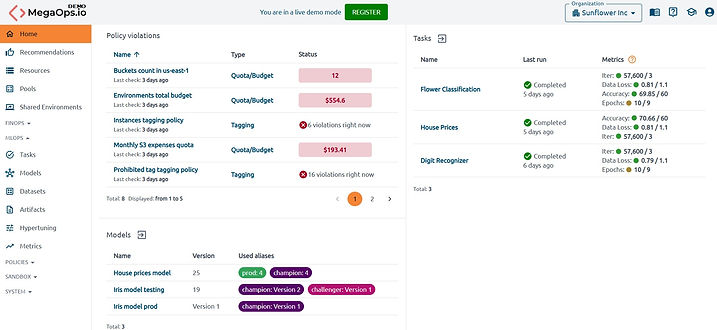
-
MLOps → Tasks section. Focus on the Last Run, Last Run Duration, and Metrics columns.

-
MLOps → Tasks → click on a task → Overview tab. Observe Tracked metrics. Tracked metrics are a graphical representation of all runs and specific numbers for the last run. Additionally, find information about the instance in which the last run was executed.

-
MLOps → Tasks → click on a task → navigate to the Runs tab. Find information about all runs on this page. The last run details are at the top of the table.
Task details page
On the Overview tab, beneath the description field, you can view the status of the metrics, including whether they reached their goals, the total number of runs, and the launch time of the last successful run. The Last Run Cost and details about the Last Run Executor are also displayed.

Find a detailed description of the page in the how-tos section of our website.
Runs Tab
Detailed statistics for each run are available in the Runs tab. The information is presented in two formats: graphical and tabular. The graph can be filtered, and you can select metrics and other parameters to display. Hovering over the graph reveals data in a tooltip. The table offers comprehensive details for each run.

Click on a run to view its Metrics, Datasets, Hyperparameters, Tags, and Charts. Artifacts and Executors are displayed in separate tabs, providing details about their location and associated costs. You can also find detailed information about the script execution, including its launch source (Git status), the executed command (command), and the console output (logs).

Model Version Tab
The table on the Model Version tab displays all versions of models from task runs, along with their parameters. Each row is clickable and provides access to detailed information.

Leaderboards Tab
Compare groups of task runs that are organized by hyperparameters and tags to determine the optimal launch parameters. This section also includes convenient functionality for comparing groups of runs.
Recommendations Tab
On the Recommendations tab, you can view recommendations for cloud instances used during training. Recommendations are available for instances used in the past 7 days.
Executors Tab
The table displays all executors for every task run.
Setting up SMTP
SMTP is the standard protocol for transmitting email messages over the internet. Configure SMTP to enable FinOps to send smart notifications to users about events and actions related to cloud cost optimization in their infrastructure.
To set up SMTP on a custom FinOps deployment:
1. Fill in these fields in overlay/user_template.yml (finops/finops-deploy/overlay/user_template.yml):
# SMTP server and credentials used for sending emails
smtp:
server:
email:
login:
port:
password:
protocol:
2. Restart the cluster with the updated user_template.yml:
./runkube.py --with-elk -o overlay/user_template.yml -- <deployment name> <version>
3. If emails are still missing after smtp configured, check the errors in kibana using query container_name: *heraldengine*.